In [34]:
import plotly.graph_objects as go
import plotly.offline as pyo
# create traces for actual and predicted values
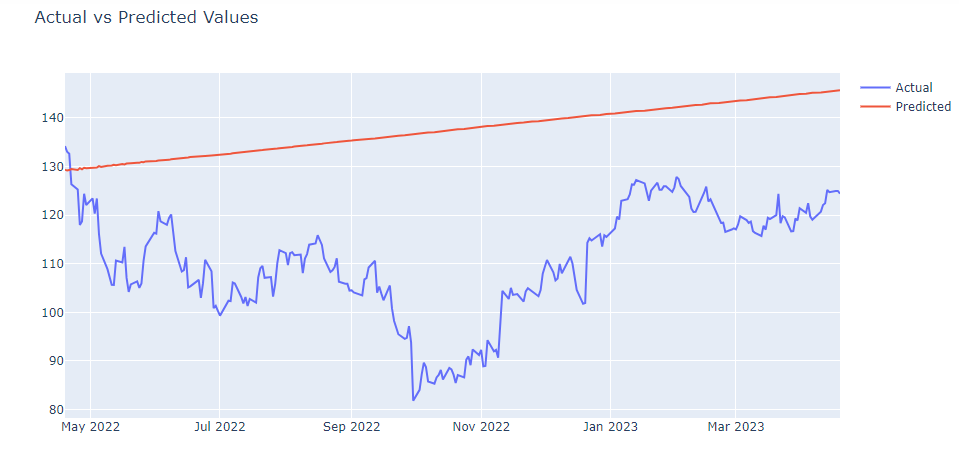
actual_trace = go.Scatter(x=test_data.index, y=test_data.values, name='Actual')
predicted_trace = go.Scatter(x=test_data.index, y=predictions, name='Predicted')
# combine the traces into a data list
data = [actual_trace, predicted_trace]
# create the layout
layout = go.Layout(title='Actual vs Predicted Values')
# create the figure
fig = go.Figure(data=data, layout=layout)
# show the figure
pyo.iplot(fig)
In [35]:
# Predict a single value from a given date input
future_date = datetime(2022, 1, 2)
future_data = model.predict(n_periods=1, exogenous=None, return_conf_int=False, alpha=0.05, start=None)
print('Predicted Adjusted Closing Price for {}: '.format(future_date), future_data)
Predicted Adjusted Closing Price for 2022-01-02 00:00:00: 1005 129.307367 dtype: float64
In [36]:
# Print the predicted value for the input date
print('The predicted value for {} is: {}'.format(future_date, future_data))
The predicted value for 2022-01-02 00:00:00 is: 1005 129.307367 dtype: float64